/
فاوا /
هوش مصنوعی آمار استنباطی و احتمال در پایتون- Inferential statistics and probability
اهم عملگرهای در پایتون Data Types Convert Data Types (تبدیل انواع دادهها) نکات کلیدی (Key Points) کتابخانه پانداس Data Reading and Writing Data Inspection and Exploration Data Selection and Filtering Data Manipulation Data Cleaning Grouping and Aggregation Data Visualization (with Matplotlib or Seaborn) Time Series Analysis مدیریت پیشرفته دادهها Advanced Data Handling متفرقه Miscellaneous کتابخانه Matplotlib نمودارهای پایه نمودارهای پیشرفته نمودارهای سهبعدی نمودارهای ویژه ترکیب نمودارها نمونه کد برای ایجاد نمودارهااهم عملگرهای در پایتون
عملگرهای ریاضی (Arithmetic Operators):
- جمع (Addition): +
- تفریق (Subtraction): -
- ضرب (Multiplication): *
- تقسیم حقیقی (Division): /
- تقسیم صحیح (Floor Division): //
- ماندهگیری (Modulus): %
- توان (Exponentiation): **
عملگرهای مقایسهای (Comparison Operators):
- برابری (Equal to): ==
- نابرابری (Not equal to): !=
- بزرگتر از (Greater than): >
- کوچکتر از (Less than): <
- بزرگتر مساوی (Greater than or equal to): >=
- کوچکتر مساوی (Less than or equal to): <=
عملگرهای منطقی (Logical Operators):
- AND منطقی (Logical AND): and
- OR منطقی (Logical OR): or
- NOT منطقی (Logical NOT): not
عملگرهای بیتی (Bitwise Operators):
- AND بیتی (Bitwise AND): &
- OR بیتی (Bitwise OR): |
- XOR بیتی (Bitwise XOR): ^
- شیفت به چپ (Left Shift): <<
- شیفت به راست (Right Shift): >>
- NOT بیتی (Bitwise NOT): ~
عملگرهای اختصاصی (Assignment Operators):
- مساوی (Assignment): =
- جمع و اختصاص (Addition Assignment): +=
- تفریق و اختصاص (Subtraction Assignment): -=
- ضرب و اختصاص (Multiplication Assignment): *=
- تقسیم و اختصاص (Division Assignment): /=
- و غیره...
عملگرهای اعضای (Membership Operators):
- عضویت (Membership): in
- عدم عضویت (Not a Membership): not in
عملگرهای هویت (Identity Operators):
- تطابق هویت (Identity): is
- عدم تطابق هویت (Not Identity): is not
این عملگرها به طور گسترده در برنامهنویسی پایتون استفاده میشوند برای انجام عملیات مختلف از جمله محاسبات ریاضی، مقایسهها، منطق برنامه، عملیات بیتی و اعمال اختصاصی بر روی دادهها.
Data Types
در زیر، اصطلاحات مربوط به تبدیل انواع دادهها (Convert Data Types) به انگلیسی و فارسی آمده است:
Convert Data Types (تبدیل انواع دادهها)
نوع دادههای پایه (Basic Data Types)
- Integer (عدد صحیح): int()
- Float (عدد اعشاری): float()
- String (رشته): str()
- Boolean (بولین): bool()
مثالها (Examples)
-
تبدیل به عدد صحیح (Convert to Integer)
num = int("123") # num اکنون یک عدد صحیح است
-
تبدیل به عدد اعشاری (Convert to Float)
num = float("123.45") # num اکنون یک عدد اعشاری است
-
تبدیل به رشته (Convert to String)
text = str(123) # text اکنون یک رشته است
-
تبدیل به بولین (Convert to Boolean)
flag = bool(1) # flag اکنون یک بولین است و مقدار آن True است
تبدیل انواع دادههای پیچیدهتر (Complex Data Type Conversions)
-
تبدیل به لیست (Convert to List)
my_list = list("hello") # my_list اکنون ['h', 'e', 'l', 'l', 'o'] است
-
تبدیل به مجموعه (Convert to Set)
my_set = set([1, 2, 2, 3]) # my_set اکنون {1, 2, 3} است
-
تبدیل به دیکشنری (Convert to Dictionary)
my_dict = dict([(1, 'one'), (2, 'two')]) # my_dict اکنون {1: 'one', 2: 'two'} است
-
تبدیل به تاپل (Convert to Tuple)
my_tuple = tuple([1, 2, 3]) # my_tuple اکنون (1, 2, 3) است
نکات کلیدی (Key Points)
این مثالها و توضیحات به شما کمک میکنند تا انواع مختلف دادهها را در پایتون تبدیل کنید و با اصطلاحات معادل آنها به زبان فارسی آشنا شوید.
کتابخانه پانداس
Data Reading and Writing
-
Read from CSV file
import pandas as pd df = pd.read_csv('file.csv')
-
Read from Excel file
df = pd.read_excel('file.xlsx', sheet_name='Sheet1')
-
Write to CSV file
df.to_csv('new_file.csv', index=False)
-
Write to Excel file
df.to_excel('new_file.xlsx', sheet_name='Sheet1', index=False)
Data Inspection and Exploration
-
Check first few rows
-
Check last few rows
-
Get information about columns
-
Summary statistics
-
Count unique values
Data Selection and Filtering
-
Select columns
-
Filter rows
df[df['column_name'] > value]
-
Select rows by index
-
Select rows and columns by index
df.loc[index, 'column_name']
-
Select rows and columns by position
df.iloc[row_position, column_position]
Data Manipulation
-
Drop columns
df.drop(columns=['column_name'])
-
Drop rows
-
Rename columns
df.rename(columns={'old_name': 'new_name'})
-
Sort values
df.sort_values(by='column_name', ascending=False)
Data Cleaning
-
Handle missing values
df.dropna() # Drop rows with NaN values
df.fillna(value) # Fill NaN values with specified valu
-
Convert data types
df['column_name'] = df['column_name'].astype('int')
Grouping and Aggregation
-
Group by
df.groupby('column_name').mean()
-
Aggregation functions
df.groupby('column_name').agg({'column_name': 'sum', 'other_column': 'mean'})
Data Visualization (with Matplotlib or Seaborn)
-
Line plot
df.plot(x='column_name', y='other_column', kind='line')
-
Scatter plot
df.plot(x='column_name', y='other_column', kind='scatter')
-
Histogram
df['column_name'].plot(kind='hist')
Time Series Analysis
-
Convert to datetime
df['date_column'] = pd.to_datetime(df['date_column'])
-
Resampling
مدیریت پیشرفته دادهها Advanced Data Handling
-
ادغام Merge DataFrames
pd.merge(df1, df2, on='key_column')
-
اتصال Concatenate DataFrames
-
جدول محوری Pivot table
df.pivot_table(index='index_column', columns='column_to_pivot', values='values_to_show', aggfunc='mean')
متفرقه Miscellaneous
-
Apply function
-
Determine unique values
df['column_name'].unique()
-
Check for duplicates
اینها برخی از دستورات و عملکردهای اساسی پاندا هستند که برای تجزیه و تحلیل دادهها، دستکاری و کارهای آماده سازی ضروری هستند. تسلط بر این موارد شما را قادر میسازد تا با استفاده از پانداها در پایتون، دادهها را به طور موثر پاکسازی، تبدیل، تجزیه و تحلیل و تجسم کنید.
کتابخانه Matplotlib
کتابخانه Matplotlib یکی از محبوبترین ابزارها برای ایجاد نمودارهای گرافیکی در پایتون است. این کتابخانه امکانات گستردهای برای رسم انواع نمودارها فراهم میکند. در زیر، برخی از توابع اصلی برای رسم نمودارهای مختلف در Matplotlib آورده شده است:
نمودارهای پایه
-
نمودار خطی (Line Plot)
-
نمودار پراکندگی (Scatter Plot)
-
نمودار ستونی (Bar Plot)
-
نمودار دایرهای (Pie Chart)
plt.pie(sizes, labels=labels)
-
نمودار هیستوگرام (Histogram)
plt.hist(data, bins=number_of_bins)
نمودارهای پیشرفته
-
نمودار جعبهای (Box Plot)
-
نمودار ساقه و برگ (Stem Plot)
-
نمودار پلهای (Step Plot)
-
نمودار ناحیهای (Area Plot)
plt.fill_between(x, y1, y2)
-
نمودار قطبی (Polar Plot)
نمودارهای سهبعدی
-
نمودار سهبعدی خطی (3D Line Plot)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot(x, y, z)
-
نمودار سهبعدی پراکندگی (3D Scatter Plot)
-
نمودار سهبعدی سطحی (3D Surface Plot)
نمودارهای ویژه
-
نمودار هیستوگرام دوبعدی (2D Histogram)
plt.hist2d(x, y, bins=[x_bins, y_bins])
-
نمودار تصویری (Image Plot)
plt.imshow(data, cmap='gray')
-
نمودار موجی (Quiver Plot)
ترکیب نمودارها
- ترکیب چند نمودار در یک صفحه (Subplots)
fig, axs = plt.subplots(nrows, ncols)
axs[0, 0].plot(x, y)
axs[0, 1].bar(x, height)
نمونه کد برای ایجاد نمودارها
import matplotlib.pyplot as plt
import numpy as np
# دادهها
x = np.linspace(0, 10, 100)
y = np.sin(x) # نمودار خطی
plt.figure() plt.plot(x, y)
plt.title("نمودار خطی")
plt.xlabel("X")
plt.ylabel("Y")
plt.show() # نمودار پراکندگی
plt.figure()
plt.scatter(x, y)
plt.title("نمودار پراکندگی")
plt.xlabel("X")
plt.ylabel("Y")
plt.show() # نمودار ستونی
categories = ['A', 'B', 'C']
values = [10, 20, 15]
plt.figure()
plt.bar(categories, values)
plt.title("نمودار ستونی")
plt.xlabel("دستهها")
plt.ylabel("مقدار")
plt.show() # نمودار دایرهای
sizes = [15, 30, 45, 10]
labels = ['A', 'B', 'C', 'D']
plt.figure()
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title("نمودار دایرهای")
plt.show() # نمودار هیستوگرام
data = np.random.randn(1000)
plt.figure() plt.hist(data, bins=30)
plt.title("نمودار هیستوگرام")
plt.xlabel("مقدار")
plt.ylabel("تعداد")
plt.show()
این نمونهها به شما کمک میکنند تا انواع مختلف نمودارها را با استفاده از کتابخانه Matplotlib ایجاد کنید و تحلیل دادههای خود را به صورت گرافیکی انجام دهید.

Base Types انواع
string str "One\nTwo" رشتهای
integer int عددی
float numeric values with floating decimal points. اعشار
boolean bool True False
Container Types انواع کانتینر
list[1,5,9] فهرست
dictionary dict {"key":"value"} واژه نامه
{1:"one",3:"three",2:"two",3.14:"π"}
collection set {"key1","key2"} مجموعه
{1,9,3,0}
List is a collection which is ordered and changeable. Allows duplicate members.
Tuple is a collection which is ordered and unchangeable. Allows duplicate members.
Set is a collection which is unordered, unchangeable*, and unindexed. No duplicate members.
Dictionary is a collection which is ordered** and changeable. No duplicate members.
Conversions تبدیل
int("15") → 15
list("abc") → ['a','b','c']
dict([(3,"three"),(1,"one")]) → {1:'one',3:'three'}
set(["one","two"]) → {'one','two'}
if bool(x)==True: ⇔ if x:
if bool(x)==False:⇔ if not x:
if age<=18:
state="Kid"
elif age>65:
state="Retired"
else:
state="Active"
Integer Sequences
range([start,] end [,step])
range(5)→ 0 1 2 3 4
range(3,8)→ 3 4 5 6 7
range(len(seq))→ sequence of index of values in seq
for var in sequence:
for x in range(5):
print(x)
Operations on Lists عملیات روی لیستها
lst.append(val) add item at end
lst.extend(seq) add sequence of items at end
lst.insert(idx,val) insert item at index
lst.remove(val) remove first item with value val
lst.pop([idx])→value remove & return item at index idx (default last)
lst.sort() lst.reverse() sort / reverse liste in place
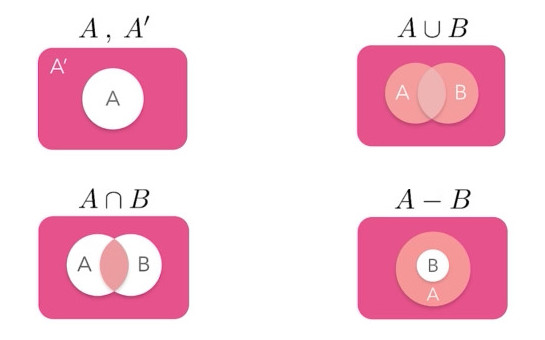
Operations on Sets
Operators:
| → union (vertical bar char)
& → intersection
- ^ → difference/symmetric diff.
< <= > >= → inclusion relations
Operators also exist as methods.
s.update(s2) s.copy()
s.add(key) s.remove(key)
s.discard(key) s.clear()
s.pop()
Set in Python مجموعه
-
Initial اولیه
- Create Set ایجاد مجموعه
- set1 = set()
- set2= {1, 2}
- Add to Set به مجموعه اضافه کنید
- Remove from Set حذف از مجموعه
- Update Set به روز رسانی مجموعه
-
Operator عمل کننده
- Intersection اشتراک
- set1.intersection(set2)
- set1& set2
- Union اجتماع
- set1.union(set2)
- set1| set2
- Difference تفاضل (آنچه در دو مجموعه نیست)
- set1.difference(set2)
- set2.difference(set1)
- set1- set2, set2- set1
- Symmetric Difference تفاضل متقارن (اجتماع منهای اشتراک)
- set1.symmetric_difference(set2)
- set1^ set2
- Product ضرب دکارتی
- from itertools import product
- list(product(set1, set2))
-
Checking چک کردن
- Membership عضو
- Disjoint اشتراک تهی است؟
- set1.intersection(s2) == set()
- set1& set2== set()
- set1.isdisjoint(set2)
- Subset زیرمجموعه
- s2.issuperset(s1)
- s1.issubset(s2)
- Superset پدر
- s2.issuperset(s1)
- s1.issubset(s2)
- Complement (منها کردن)
- U = set(range(1, 11))
- s1 = {4, 5, 6}
- print(U - s1)
- PowerSet خارج کردن تمام مجموعهها
- from itertools import combinations as comb
- s1 = {1, 2, 3, 4}
- for lng in range(0, len(s1)+1):
- print(list(comb(s1, lng)))
- Problem
- Counting
- Permutation جایگشت
- Combination ترکیب
- Combination with Replacement
- Product
- Generation
- Repeat
- Count
- Cycle
- Merging
- Accumulate
- Chain